All ProgramsLive
TermaVision
Making centuries of Buddhist iconographic knowledge searchable.
2025–present
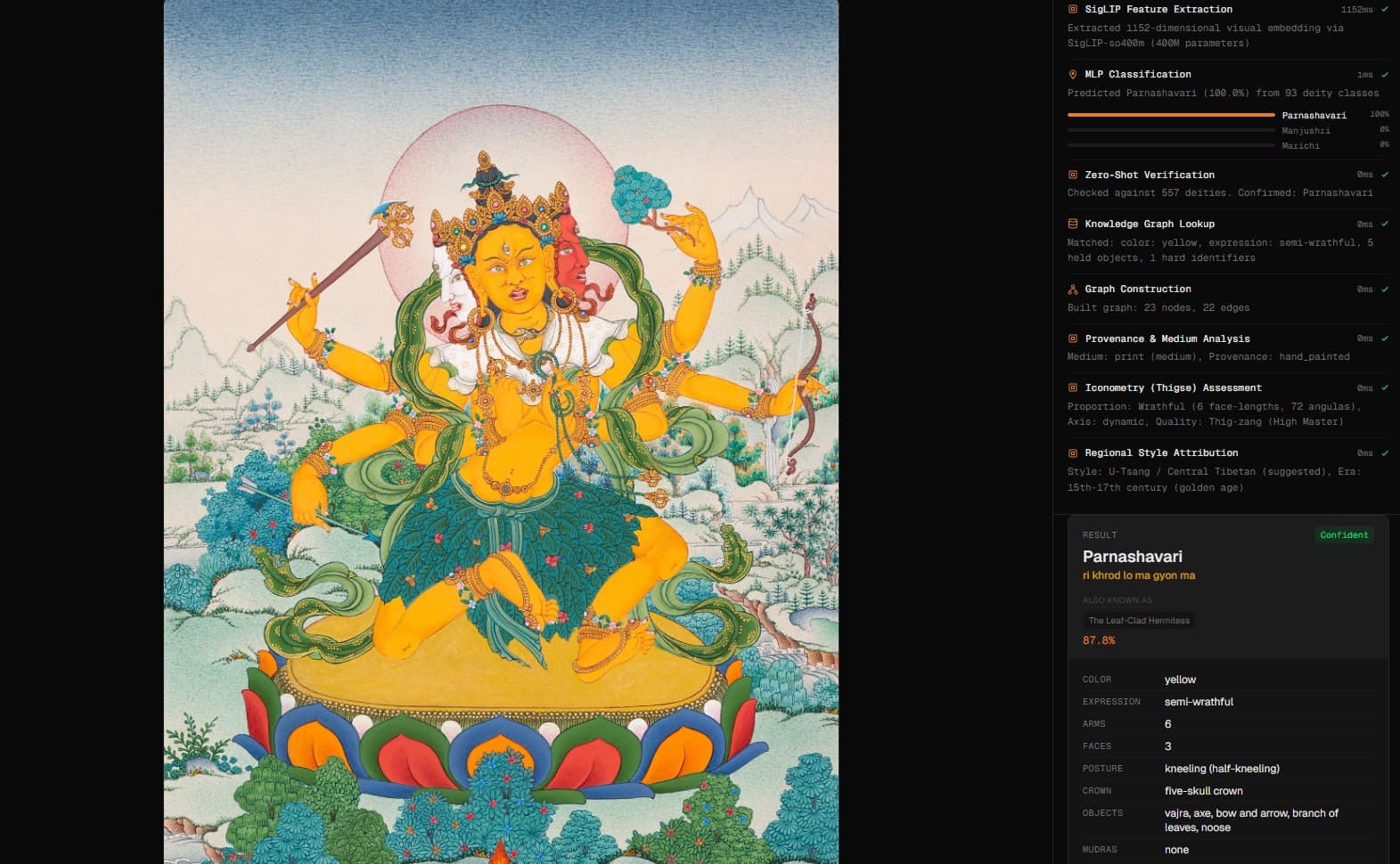
Overview
Identifying a deity in a thangka has always required deep specialist training. TermaVision puts that knowledge within reach of scholars, conservators, and students through a purpose-built vision model.
94.4%
Top-1 Accuracy
93
Deity Classes
557 deities
Knowledge Graph
What’s Inside
1
Multi-stage deep-learning pipeline purpose-built for Buddhist art — not a generic AI
2
93-class deity classification across Tibetan, Himalayan, and broader Buddhist traditions
3
Hand-built iconography knowledge graph of 557 deities with structured attributes
4
Compositional reasoning encoding 8 canonical Buddhist figure groupings
5
Published methodology in peer-reviewed research
How It’s Built
Stage 1 — Figure Detection
Locates every individual figure in the artwork, even in complex multi-figure thangkas. Adapts automatically — no retraining needed when new figure types are added.
Stage 2 — Figure Classification
Each detected figure is isolated and classified independently against 93 trained classes. The model is purpose-built and lightweight — not a general AI repurposed for this task.
Stage 3 — Iconographic Verification
Every identification is cross-checked against a hand-built database of 557 deities — verifying body color, hand gestures, sacred objects, and posture.
Stage 4 — Compositional Reasoning
The system understands how Buddhist figures appear together. Knowledge of 8 traditional groupings allows it to use context.
Stage 5 — Validation
Color mismatch detection, duplicate detection, and confidence calibration.
Research & Publications
TermaVision: A Multi-Stage Deep Learning Pipeline for Automated Buddhist Iconography Identification
Thupten N. Chakrishar · 2025
Abstract
This paper presents TermaVision, an automated multi-stage pipeline that combines frozen vision-language features, a lightweight classifier, zero-shot attribute verification, and a structured iconography knowledge graph to identify Buddhist figures in thangka paintings, statues, and murals. The system achieves 94.4% top-1 accuracy across 93 classes, processing images in 1.3–4 seconds on a consumer GPU.
Key Findings
94.4% top-1 accuracy across 93 deity classes using a purpose-built vision model
557-deity iconography knowledge graph with 9 attribute categories
Compositional reasoning module encoding 8 canonical Buddhist figure groupings
Processes images in 1.3–4 seconds vs. 8–35 seconds for the prior system
Buddhist art identificationdeep learningknowledge graphiconographycultural heritage